Disclaimer. This post originally was written about a year ago and some things could be changed. But it is still relevant, and I decided to translate and post it without any changes to explain my point and creation of the Maigret tool.
Not so long time ago I took a look at username checking tools. The most popular ones are namechk.com, whatsmyname.app, sherlock, snoop.
Each of them is good at something, but I can’t fully trust the results of any of them. I went through all the known tools, both scripts, and sites. I asked around colleagues and gathered statistics of use cases. And I made a disappointing conclusion — I don’t have any satisfactory tool for searching by a nickname.
What do I mean by “satisfactory”? And what to do with it? I will try to explain further.
Branding tools
I will immediately reveal the secret of Punchinelle — most of the tools for searching by nickname are not related to OSINT, but marketing.
Yes, they are recommended on every corner, even by experts. But let’s take a closer look at what they offer!
First, we’ll examine the search by domain tools from Namechk. This is an interesting approach, and for sure it sometimes yields results for a person’s nickname. But the purpose of this search is to find available domains to buy and promote your brand.

Now we’ll take a look at accounts searching. Tools such as Namechk, InstantUsername, Checkusernames offer a way to check that the name is not taken. These services are not intended to find a person’s profiles, their logic is exactly the opposite to our intention, and also does not require high accuracy.

For example, KnowEm offers a way to register the desired nickname on 300 sites for money. What do you think? Is it more profitable for them to find existing accounts by a nickname or check if there are unused usernames available for sale?
Quantity and quality
Even a site that is irrelevant at first glance can provide useful information. For example, we can find some account on the forum where our target has left very valuable messages. Or on a specific little-known social network, where the account was once created for contact with a friend who is nowhere else.
A tool with a lot of sources is good, anyway, we need to consider it using other metrics. Other than the number of checked sites.
Quality
We only need correct results, with a minimum of false positives. We will discuss this in more detail in the next section.
Ranging
It is important for us to understand which sites are more important to get the result faster when analyzing them. Sherlock knows how to rank sites using Alexa top charts, which seems a very reasonable way to classify sources. This is an objective assessment, showing the “weight” of the site and its importance to people. Unfortunately, this kind of information isn’t reflected in the report.
Snoop developers have grasped this need well: their sites are divided by region, and there is a worldwide region for the world’s used. And in the HTML-report it is possible to sort this classification using this approach, but anyway there isn’t internal ranking by group, so it will be difficult to figure out which of the ten worldwide services is more relevant.

Categories
WhatsMyName divides the sites into categories, and this is very convenient, allows you to quickly filter what you need. Definitely, a must-have, but this feature isn’t present in any other tool.
The main idea is “the more data becomes, the more cuts we need to analyze it”.
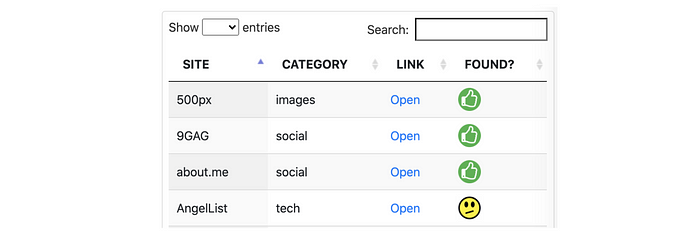
Customization
Of course, the user’s needs may vary. In some investigations user needs not all the sites, or, in some case, only English-language or only gaming sites. It could happen that during an investigation he may need a check on a subset of sources or a search on a little-known site.
The tool should allow such tuning, and both online services and proprietary paid tools like snoop don’t permit this kind of work.
False positives
It is worth highlighting 3 categories here:
1) False negative
The account isn’t found on the site, but it is present.
We didn’t get the full expected result, or we don’t find out about this site at all, so we need to run another tool and merging the results (or checking manually on Google).
It is maybe acceptable to lose search results from one unimportant site, but what to do if there are a dozen of such sites with a taken username?
This is the most painful problem of all false positives, as evidenced by a survey of colleagues.
2) False positive technical
The account was found on the site, but it isn’t present.
It would seem that in any case we will go through each site and check for it. But the lack of an account is not so obvious everywhere, and it may take you a couple of minutes to check it by yourself.
What if we run several tools and each one fails on different sites? Can we make a report without analysis? Looks like we can’t trust the search results and we’ll need to proceed with manual verification.
So we will waste extra time.
3) False positive actual
The account is found on the site, but it belongs to another person.
Well, it happens, especially with a not very unique name. Unfortunately, the analytical work for cutting off such cases is still difficult to assign to scripts.
What to do to avoid false positives? This kind of issue could happen due to naive verification methods (by response code or redirect). To avoid this case the developer needs to learn the sites’ structure and find a workaround to retrieve the needed information.
Socialscan went farthest in this direction. It checks the availability of the name through the official API — no failures and sudden changes, as well it has the ability to check email. Due to this strong verification approach, it supports only 12 sites.
A lot of false positives could occur due to an unexpected response — stubs, captchas, and something like that. We will analyze it below.
Censorship and Cloudflare
There are specific reasons which determine that some false positives are results of censoring, service restrictions, and protection from bots techniques.
In general, everything is clear with the first cause, censoring. If the provider has restricted access to the site by some region or IP, the easiest way is to use a proxy / VPN to bypass such restriction. It must be considered that there is censorship in different countries so it could be hard to handle information about which proxies I need for which country
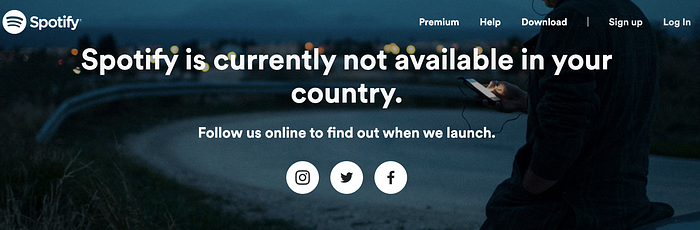
The services themselves often restrict access to some geolocations. For example, Spotify and CashMe are not available in Russia. Sherlock developers do not even try to check this and consider the stub of the response as confirmation of the existence of an account.
Snoop warns about censorship on errors and recommends using a VPN. Sounds good, but doesn’t solve the problem — snoop doesn’t even have Spotify and CashMe in the paid base. It feels like the developer himself could not use the proxy to “reduce” false positives for such sites.
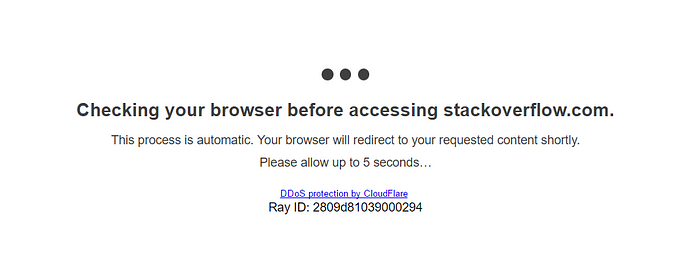
The story is similar with protection against bots: as a rule, basic antifraud can be bypassed by disguising as a normal user through request headers, cookies, IP of the desired country. This requires an even more thorough elaboration of the verification method, but it is not an insurmountable problem.
Up-to-date sites database
Now a little information about timely data update.
Modern websites are changing very quickly to accommodate the demands of the business. And even enhancing privacy can be such a requirement, which leads to the impossibility of checking the existence of an account on the site.
It becomes important not just to find and fix a method for checking the account once, but to quickly change or adapt it in case of any failure or website changes.
For example, tests (and CI general) indirectly help this — these techniques are implemented in sherlock, each site is checked regularly. However, new errors are ignored by developers, and as a result, many sites that stopped working are deleted after GitHub issues. To update the database, you need to manually pull changes from the repository! I doubt you do this every time you start an investigation.
Snoop went further and made launch parameters to update the database and script directly from its repository. I like this approach. Moreover, I believe that it is necessary to make it possible to mark false positives and problems right in the tool itself, giving operational information to the developers.
Thus, the feedback loop is narrowed to a minimum, and you get relevant ways to check accounts faster => you get fewer errors.
Of course, it’s all required a lot of time to develop and maintain. And, of course, it’s difficult. I watch amazing things such as an accidental return of unsupported sites in sherlock (commit to delete, commit to return).
Identifiers and cross-references
For some time I researched account IDs (Google // GAIA ID, Yandex with its own multiple IDs) of different platforms and their use in OSINT.
With just one link to a shared file in Yandex.Disk, you can get a nickname, public ID, and links to profiles in other Yandex services (even where the nickname is not used). This kind of process can be automated.
Some time ago in DC7495 I presented this study as theoretical, then the socid_extractor tool grew out of this — it allows you to pull out not only IDs from pages but also links to accounts specified by the person on other sites.
How can this procedure be useful for our investigation? Based on only one nickname, the tool can pivot and found profiles of a person on other sites with other nicknames. It can search through new nicknames, and determine accounts associated with internal platform IDs.
I have already suggested to the sherlock developers to use this, but the matter has not moved off the ground yet.
So what?
Let’s summarize and form a list of requirements for a satisfactory tool for searching by a nickname.
- maximum sites to check: some tools already have 1K sites, it makes no sense to aim at a smaller number;
- no false results: an existing account must be found or there must be an obvious error;
- the database of sites is promptly updated: for example, every time the tool is launched, updates are pulled from the cloud;
- readable report with ranking and categories: at least CSV/HTML + separation by country and purpose of sites;
- customization: simple addition of your own categories and sites;
- reliability of verification methods: the tool should not fail and be able to detect stubs with protection, authorization, captchas, and specific redirects with censorship of the provider or the site itself;
- the possibility of massive checking on the list of nicknames: we did not discuss this, but everything is obvious here.
And additional wishlist — these opportunities already available, but stubbornly ignored in OSINT:
- extracting links to other accounts from the page and searching them: the tool can unravel a complex tangle of related names and find all other target’s nicknames;
- automatic use of suitable proxies to bypass restrictions: there are ready-made collecting and filtering tools;
- screenshots of pages or saving to a web archive: very important for operational searches, when after a couple of hours the account can be closed/deleted.
Conclusion
So, we examined the pros and cons of the existing tools. What to do next?
Of course, make a new tool, which will be satisfactory, and I plan to do it soon.

So I have developed such a tool make a Sherlock fork called Maigret. I should admit, that haven’t realized everything that I considered necessary. But most of the features of my tool are not yet available in other tools, so this is make Maigret the most satisfactory for me. And for you?
My Telegram channel: https://t.me/osint_mindset
To discuss: https://t.me/joinchat/Fo4X2RvYX7Wxqd3ggR55mQ
